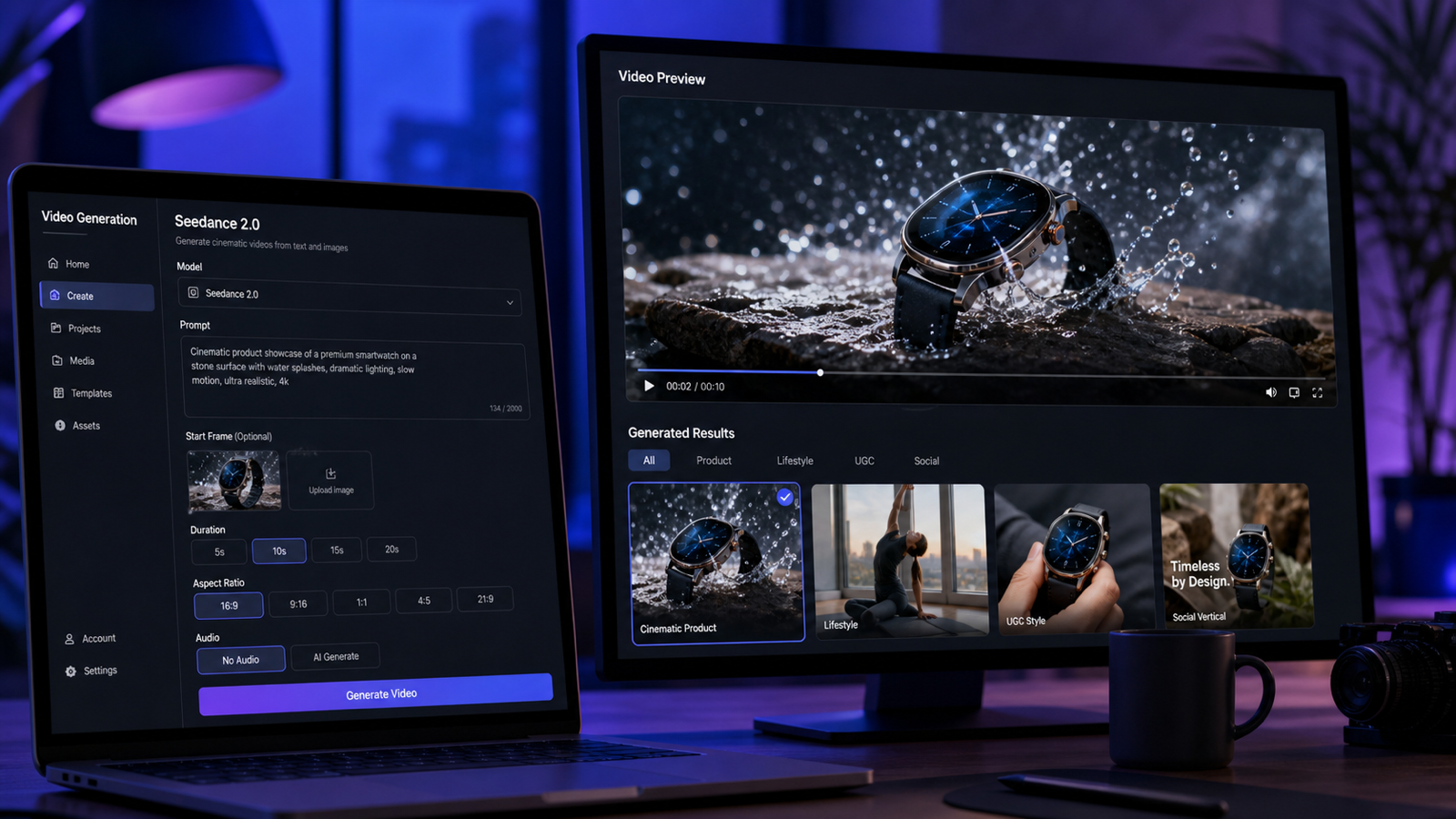
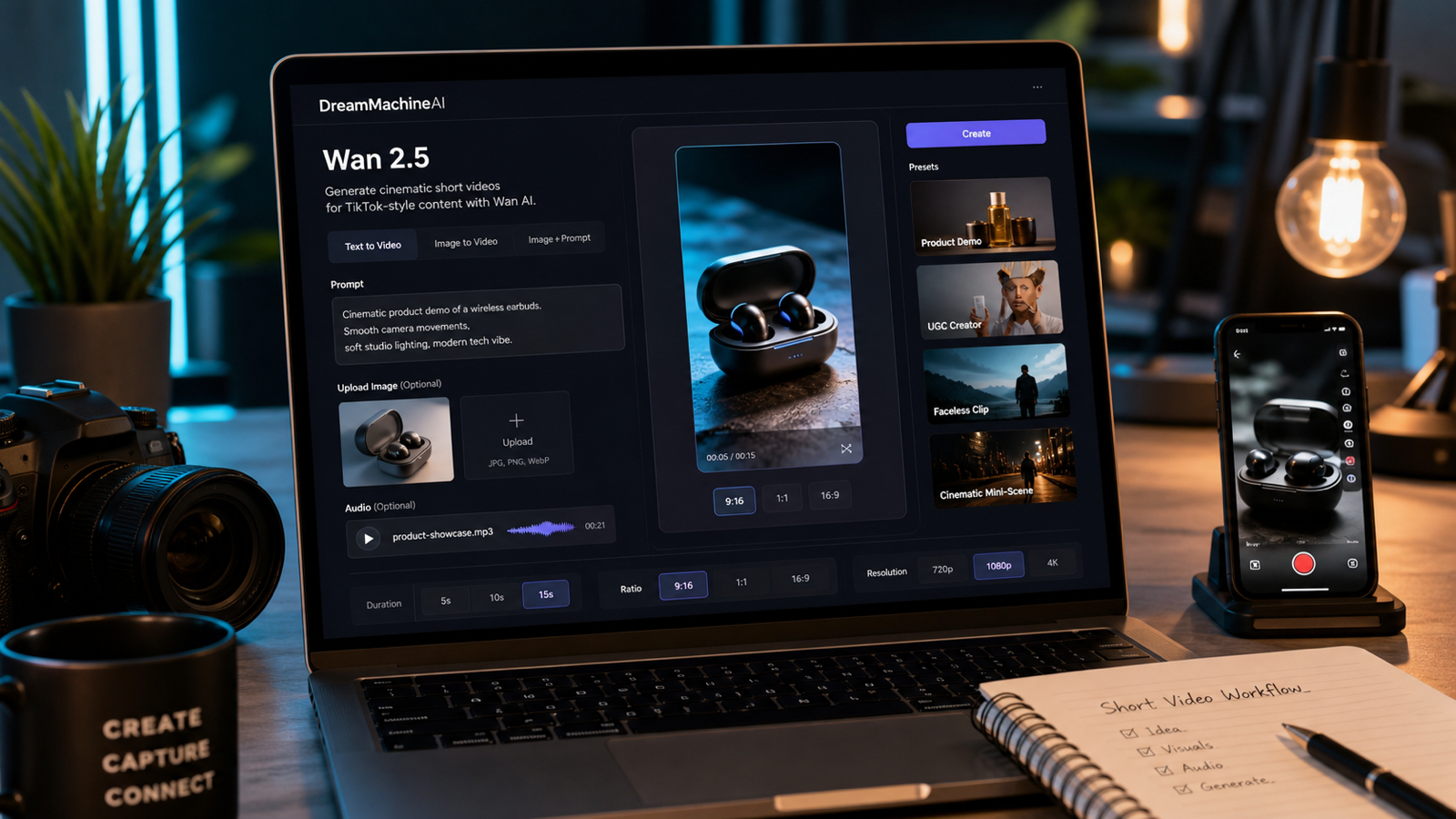
最近AI動画ジェネレーターを試しているなら、きっとこんなことに気づいているはずです。多くの比較は、技術的すぎる(「潜在一貫性」「時間的コヒーレンス」)か、あるいはあいまいすぎる(「こっちのほうがよさそう」)かのどちらかです。
でもクリエイターに本当に必要なのは、もっとシンプルで実践的な答えです。
- 自分の目的には、どのモデルを使えばいいのか?
- 手元にある入力は何か(テキスト・画像・動画)?
- ムダ打ちせずに、どうすれば早く良い結果にたどり着けるか?
このガイドでは、実際のAI動画制作において Veo 3.1 と Luma Ray2 を比較し、そのうえで両方を DreamMachine AI 内でスムーズに使う方法を紹介します。
クイックスタート:30秒で決めるなら
最速の選び方はこれです。
こんなときは Veo 3.1 を選ぶ
- テキスト主導のストーリーテリング が強く、プロンプトの指示が伝わりやすい
- 音付き動画 を作りやすく、特に Veo 3.1 のネイティブ音声生成 を試したいとき
- 予告編やストーリーシーン、マルチショット風のクリップに向いた「シネマティック」な質感
まずはここから:Veo 3.1 でのAI動画生成
こんなときは Luma Ray2 を選ぶ
- 画像や既存映像からスタート するときに強い
- クリエイティブな試行錯誤を素早く回したい、スタイライズされたライティングやモーション重視のクリップがほしい
- Ray2 video-to-video や Ray2 image-to-video モデル のような柔軟なワークフローを使いたい
まずはここから:Luma Ray2 でのAI動画生成
迷っているならシンプルです。同じプロンプトを両方のモデルに投げて、best text-to-video model ハブから並べて比較するのがいちばん確実です。
モデルごとの得意分野(誇張なし版)
難しい話は抜きにして、平たく整理します。
Veo 3.1: 「頭の中にシーンが見えている」とき向き
すでに物語のイメージがある(短くてもOK)とき、Veo 3.1 は出発点として有利になりがちです。たとえば:
- ミニ予告編
- シネマティックな一瞬のシーン
- 制御されたカメラワーク(プッシュイン、ドリー、スローパン)
- 明確な「主役+行動+雰囲気」
ワークフローの起点がテキストなら、Veo 3.1 でのAI動画生成 は多くの場合扱いやすい選択肢です。
そして「完成した映像」に近づけたいなら、意外と音の影響は大きいです。ほんの少し環境音を足すだけでも、「無音アニメーション」ではなく「ちゃんとした動画」に感じられるので、Veo 3.1 のネイティブ音声生成 を試してみる価値があります。
Luma Ray2: 「ビジュアルはあるから、とにかく動かしたい」とき向き
Ray2 が本領を発揮するのは、出発点がすでに「絵」で決まっているときです。
- キャラクターのポートレート
- 商品写真
- ムードボード的な1カット
- 変形させたい既存の動画クリップ
Ray2 は、素早く試しては作り直すタイプのクリエイターに向いており、「ダイナミックなライティング+モーション」の空気感を出しやすいモデルです。画像からスタートするなら Ray2 image-to-video モデル、映像からなら Ray2 video-to-video がおすすめです。
本当に効いてくるポイントでの比較
抽象的なベンチマークではなく、日々の制作で効いてくる観点で比べます。
1) テキスト→動画:プロンプトの忠実度とストーリーのわかりやすさ
プロンプトがミニ脚本のような場合、気にすべきは:
- 主役がきちんと一貫しているか
- 指定したアクションが再現されているか
- カメラ指示が守られているか
Veo 3.1 はテキスト主導のプロンプトに対して比較的「素直」に動く傾向があるため、物語性のテストは Veo 3.1 でのAI動画生成 から始めるクリエイターが多いです。
コツのひとつは、プロンプトをレイヤーで書くことです。
- レイヤー1(主役+場所):誰/何が、どこにいるか
- レイヤー2(アクション):何が起きるか
- レイヤー3(カメラ):どう撮るか
- レイヤー4(スタイルの縛り):ムード、光、リアルさの度合い
同じフォーマットのプロンプトで両モデルを比べたいときは、best text-to-video model ページを基準に使うと便利です。
2) 画像→動画:構図の維持 vs モーションの付加
「この画像を動かすだけ」と聞くと簡単に思えますが、良い結果には次の2つが必要です。
- 残すべき要素を守る(顔、構図、服装、商品の形など)
- それっぽい動きを足す(髪や布の揺れ、呼吸、カメラの微妙なブレなど)
この用途では、もともと「ビジュアルを動かす」ことを意識して作られている Ray2 が多くの場合扱いやすいです。画像中心のワークフローなら Ray2 image-to-video モデル を使うとよいでしょう。
3) 動画→動画:スタイル変換と反復制作
すでに映像素材がある場合──ラフ撮影、商品クリップ、過去の生成結果など──video-to-video を使うと時間を節約できます。
こんなときに有効です:
- モーションはそのままに、見た目だけ変えたい
- 季節限定の雰囲気に変えたい(ホリデー、ネオンなサイバー感、ヴィンテージフィルムなど)
- 広告のバリエーションを手早く増やしたい
ちょうどこの用途にハマるのが Ray2 video-to-video です。
4) 音:サウンドで成果物のレベルが変わるとき
多くのクリエイターは、あるタイミングまで音を後回しにしがちですが、実は 音が入るとAI動画は一気に「本物っぽく」なります。
目的が以下のようなときは:
- 予告編的な短いクリップ
- ショートのシネマティックシーン
- 冒頭数秒で「存在感」を出したいSNS投稿
…一度は Veo 3.1 のネイティブ音声生成 を試してみる価値があります。シンプルな環境音だけでも、「見て終わる」から「見続けてもらえる」映像に変わりやすくなります。
5) 速度 vs 品質:まずはラフ、最後に本気
いちばん効率の良いやり方は、「一発で完璧なプロンプトを打つ」ことではありません。おすすめは次の流れです。
- まずはラフとしてざっくり生成する
- その中から一番いいバリエーションを選ぶ
- プロンプトを「1つの要素だけ」変えてブラッシュアップ
- 内容に手応えが出た段階で、改めて本気の最終生成
このほうが試行回数を減らせるうえ、最終的なクオリティも上がりやすいです。
DreamMachine AI 上でのおすすめワークフロー(ステップごと)
DreamMachine AI を使えば、入力アップロード・プロンプト・モデル比較・反復生成まで、ワークフローを1カ所にまとめられます。
ワークフローA:テキスト→動画(スクリプト → ショット → 完成)
ゼロからシーンを作りたいとき向きです。
- best text-to-video model ハブを開く。
- ワンセンテンスでシーンの目的を書く(できるだけシンプルに)。
- カメラの動きとライティングを足す。
- 2〜4パターン生成する。
- いちばん良いものを選び、そこから詰める。
テキスト→動画のベースラインをはっきりさせたいなら、Veo 3.1 でのAI動画生成 から始めると比較しやすいです。
ワークフローB:画像→動画(キービジュアル → モーション)
強い1枚絵があるときに最適です。
- 主役がくっきりしていて、背景がごちゃついていない画像を選ぶ。
- その画像をスタートフレームとしてアップロード。
- シーンに合った動きをプロンプトする(風、呼吸、ゆっくりしたカメラの寄りなど)。
- 生成して、動きの強さを調整する。
このルートには Ray2 image-to-video モデル を使います。
ワークフローC:動画→動画(既存クリップ → 新しいスタイル/エネルギー)
素早くクリエイティブのバリエーションを出したいときに最適です。
- 動きがはっきりしている短いクリップをアップロード。
- 「モーションとフレーミングはそのまま、スタイルと雰囲気だけ変えて」といったプロンプトを書く。
- 2〜3パターン生成する。
- ベストを残しつつ、1つの要素だけ変えながらさらに詰める。
この用途には Ray2 video-to-video を使います。
ワークフローD:音付き動画(ビジュアル → 音声込みの完成形)
「仕上がった感」のある結果が欲しいときに適しています。
- シンプルでシネマティックなプロンプトから始める。
- 「環境音+1〜2個の効果音」というイメージで音の指示を短く足す。
- 最初の試行では、視覚情報はあえて複雑にしすぎない。
このとき Veo 3.1 のネイティブ音声生成 が強みとして活きます。
コピペOKのプロンプトテンプレ(モデル共通)
ここから括弧の中だけ入れ替えて使えます。
テンプレ1:シネマティックなテキスト→動画
プロンプト:
A [subject] in a [setting], [action]. Cinematic lighting, soft shadows, realistic textures. Slow camera [move] with shallow depth of field. Mood: [mood].
例:
A lone traveler in a rainy neon alley, slowly turning to look over their shoulder. Cinematic lighting, soft shadows, realistic textures. Slow camera push-in with shallow depth of field. Mood: tense, mysterious.
テンプレ2:商品紹介(UGC向き)
プロンプト:
Close-up product shot of [product] on [surface]. Natural daylight, clean background. Subtle handheld feel. The product rotates slightly as light glints across details. Crisp focus, commercial style.
テンプレ3:スタイライズされたシーン
プロンプト:
A stylized [genre] scene of [subject] in [setting], [action]. Strong color palette, dramatic lighting, smooth motion. Camera [move].
テンプレ4:動画→動画のスタイル変換
プロンプト:
Keep the original motion and framing. Transform the clip into [style]. Update lighting to [lighting]. Preserve subject identity and main shapes.
ユースケース別のおすすめ(迷わないために)
ショートフィルム/予告編シーン
- シーンの分かりやすさ重視なら Veo 3.1 でのAI動画生成 から
- 仕上げに Veo 3.1 のネイティブ音声生成 で音も試す
UGC広告/商品プロモーション
- バリエーションを手早く出すには Luma Ray2 でのAI動画生成 が便利
- すでに動画素材があるなら Ray2 video-to-video をメインに
画像主導のアニメーション(キャラ、ポスター、キーフレーム)
- Ray2 image-to-video モデル から始めるのがおすすめ
教育・解説系のビジュアル
- プロンプトの指示をきちんと守ってほしいときは Veo 3.1 でのAI動画生成 を優先
トラブルシューティング:ありがちな問題の直し方
どちらのモデルでも効きやすい対処法をまとめます。
- チラつき/細部の不安定さ → シーンの情報量を減らす。動くオブジェクトを増やしすぎない。
- 顔が崩れる・変わる → カメラの動きを穏やかにする。「極端な」スタイル指定を減らす。
- プロンプトが無視される → 文を短くする。いちばん重要な指示を最初の1文に持ってくる。
- 動きがフワフワしている → 「重さ」の指定を入れる:“grounded movement”, “realistic physics”, “subtle motion” など。
- 背景がごちゃごちゃする → シンプルな環境を指定する。“clean background” などが効きやすい。
- 演出が派手すぎ/カオス → 形容詞を減らし、スタイルの方向性はひとつに絞る。
- 色がコロコロ変わる → パレットを固定する:“warm golden tones” や “cool blue tones” など。
- カメラが落ち着かない → カメラ指示は1つだけ(push-in か pan か tilt のどれか1つ)。
- 主役が別人になる → 年齢・服装・特徴など、アイデンティティを具体的に書く。
- どうしてもシネマティックに見えない → 光とレンズの言葉を足す:“soft shadows”, “shallow depth of field”, “cinematic lighting” など。
FAQ
テキスト→動画なら、Veo 3.1 と Ray2 どっちがいい?
ワークフローの起点がテキストで、「シーンを思いどおりにコントロールしたい」場合、多くのクリエイターが Veo 3.1 でのAI動画生成 から始めています。
Ray2 は image-to-video と video-to-video の両方に向いている?
はい。この2つは Ray2 を使う主な理由のひとつです。静止画から動かすなら Ray2 image-to-video モデル、映像の変換には Ray2 video-to-video を試してみてください。
Veo 3.1 は音声生成に対応している?
音付きの出力を試したい場合は、Veo 3.1 のネイティブ音声生成 から始めるとよいです。
両モデルを手っ取り早く比較するには?
同じプロンプトを使い、best text-to-video model ハブから連続で生成して比較するのがいちばん簡単です。
DreamMachine AI で試せるその他のツール(リンク付き)
フルのAI動画ワークフローを組むなら、いろいろなモデルや入力をすぐ試せる「クリエイター用スイッチボード」があると便利です。
- モデルをまたいで比較・生成する起点:best text-to-video model
- Veo モデルページ:Veo 3.1 でのAI動画生成
- Ray2 モデルページ:Luma Ray2 でのAI動画生成
プラットフォーム上の他ツールを見て回りたい場合は:
https://dreammachineai.online/
まとめ
ざっくり言えば、こう考えると選びやすくなります。
- テキスト主導のストーリー+音の実験 → Veo 3.1
- 画像/動画主導の制作+素早いバリエーション出し → Ray2
そして何より、どちらか一方に「永遠に決め打ち」する必要はありません。DreamMachine AI 上では、両者を補完し合うツールとして扱えます。
片方は物語のコントロールに強く、もう片方はビジュアルの変換と反復制作に強い、という役割分担です。
あとは、ひとつのプロンプトを両モデルに通してみて、いちばん良い結果を保存し、そこから少しずつ詰めていくだけで、試行回数を抑えつつクオリティの高い結果にたどり着きやすくなります。